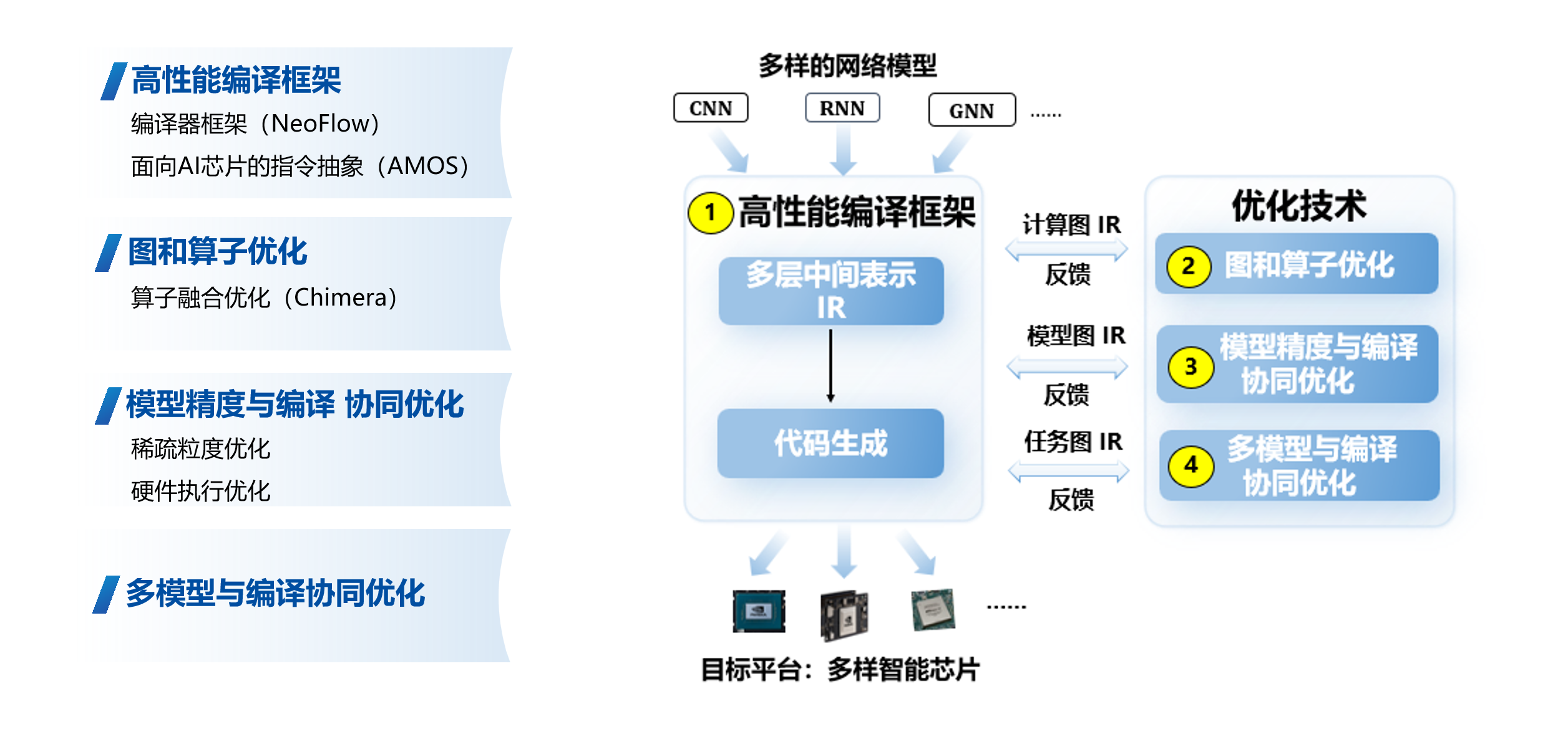
AI赋能技术研究中心聚焦人工智能与系统软件、芯片架构的深度协同,面向新一代AI芯片与异构计算平台,开展高性能编译框架与智能优化技术研究。中心围绕“模型—编译—硬件”全栈协同优化这一核心目标,系统推进编译器技术、指令抽象、图与算子优化以及硬件执行优化等关键方向的研究与工程化落地,为AI应用在多样化硬件平台上的高效部署提供核心技术支撑。
目前,中心已形成一套较为完整、具备持续演进能力的AI编译与优化技术体系,主要包括以下方向:
(1)高性能编译框架与编译器系统(NeoFlow)
中心自主研发高性能AI编译框架 NeoFlow,面向多类型AI芯片与异构计算平台,提供从模型表示、计算图优化到后端代码生成的统一编译基础设施。该框架具备良好的可扩展性与模块化设计,支持多前端模型接入与多后端硬件适配,为上层AI模型优化和下层硬件执行优化提供稳定高效的编译支撑。
(2)面向AI芯片的指令抽象机制(AMOS)
针对AI芯片架构多样化、指令集差异显著的问题,中心提出并实现了面向AI芯片的指令抽象机制 AMOS(Abstract Machine for Operator Scheduling)。通过统一的指令与执行语义抽象,降低编译器与底层硬件的耦合度,提升编译框架对不同AI加速器和专用指令架构的适配效率,加速AI芯片软件生态的构建。
(3)计算图与算子优化技术(Chimera)
在AI模型编译过程中,中心重点研究计算图级与算子级优化技术,研发了算子融合与重写优化系统 Chimera。该系统通过对模型计算图进行全局分析,实现跨算子融合、访存优化与计算重排,显著降低内存访问开销与调度成本,有效提升模型在实际硬件平台上的执行性能与能效表现。
(4)模型精度与编译协同优化技术
围绕模型精度与编译优化之间的协同关系,中心开展模型感知的编译优化研究,重点关注稀疏化与低精度计算场景下的稀疏粒度优化问题。在保证模型精度可控的前提下,通过编译层面的结构化优化与映射策略,充分释放硬件计算潜力,实现性能与精度的协同提升。
(5)面向硬件执行的编译优化与多模型协同优化
针对实际应用中多模型并发部署和复杂执行环境,中心研究面向硬件执行特性的编译优化技术,包括任务调度、资源分配与执行流水优化等。同时,探索多模型与编译协同优化方法,通过统一建模与联合调度,提高系统整体吞吐率与资源利用效率,满足云端与边缘场景下的多样化AI应用需求。